Database-side debounce

Hidekazu Kubota
Creator of GitDocumentDBDatabase-side debounce has been experimentally implemented in GitDocumentDB v0.4.5.
Debounce is a commonly used feature in UI development. Debounce is also well known to be provided by Lodash and RxJS. Debounce executes an enqueued task only when a debounce time has passed without any other enqueued tasks. If a new task is enqueued before a debounce time passes, the previous tasks will be dropped and not executed, and a new debounce time is scheduled.
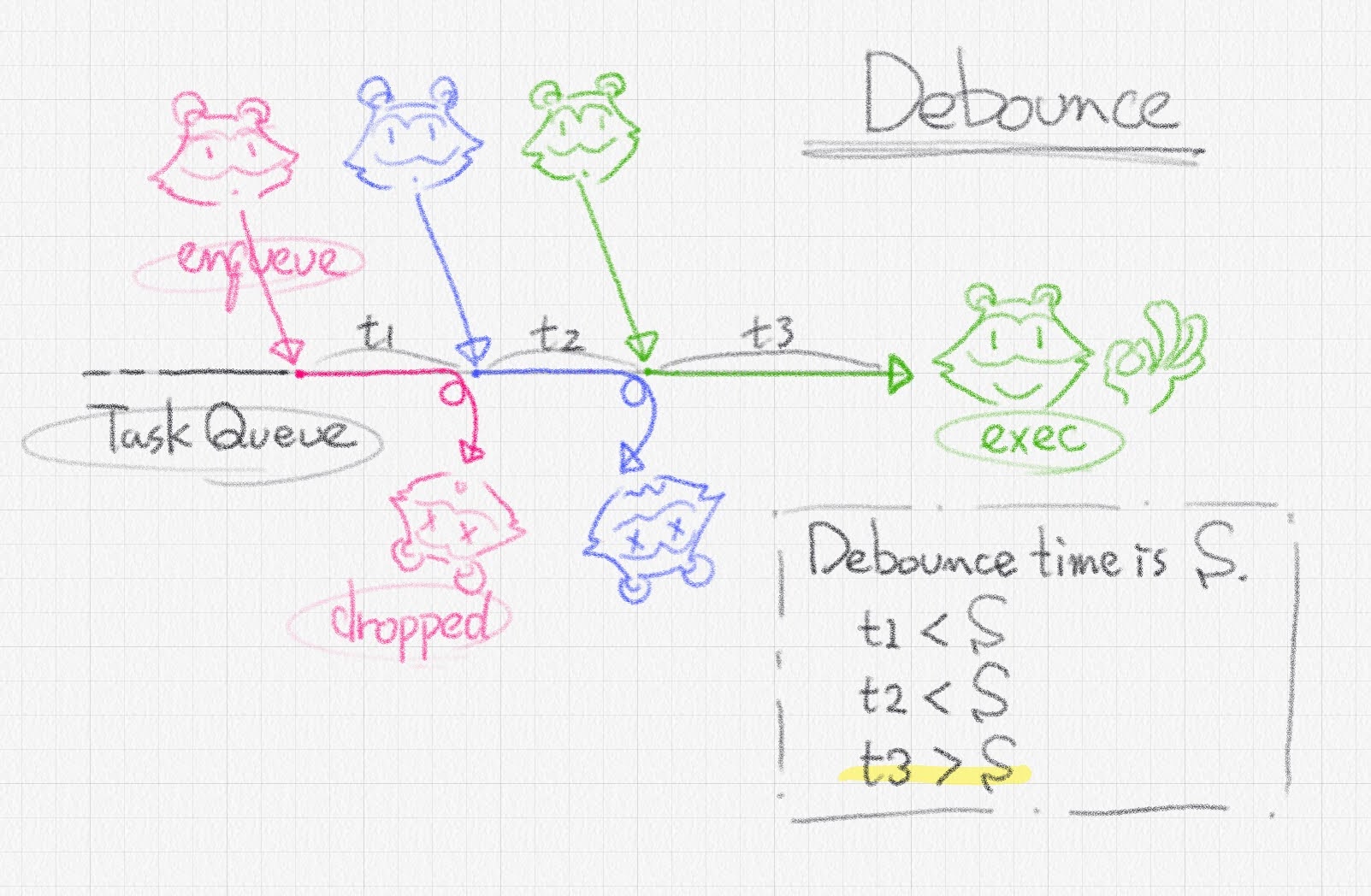
Such a feature can reduce the processing load when continuously retrieving data from a server or persisting data from a (redux) store.
In the same way, debounce in GitDocumentDB drops consecutive 'put' or 'update' tasks to the same id document.
Database-side debouncing is intended to simplify the data store persistence procedure on the application side, especially in data flows involving DB synchronization and exclusive locking on the application side.
The data flow between a DB with an eventual consistency sync model, such as GitDocumentDB, and an app's Redux store is a cyclic graph and causes a race case. UI event updates both the store and a document in the database. Sync event also updates both the same document in the database and the same store.
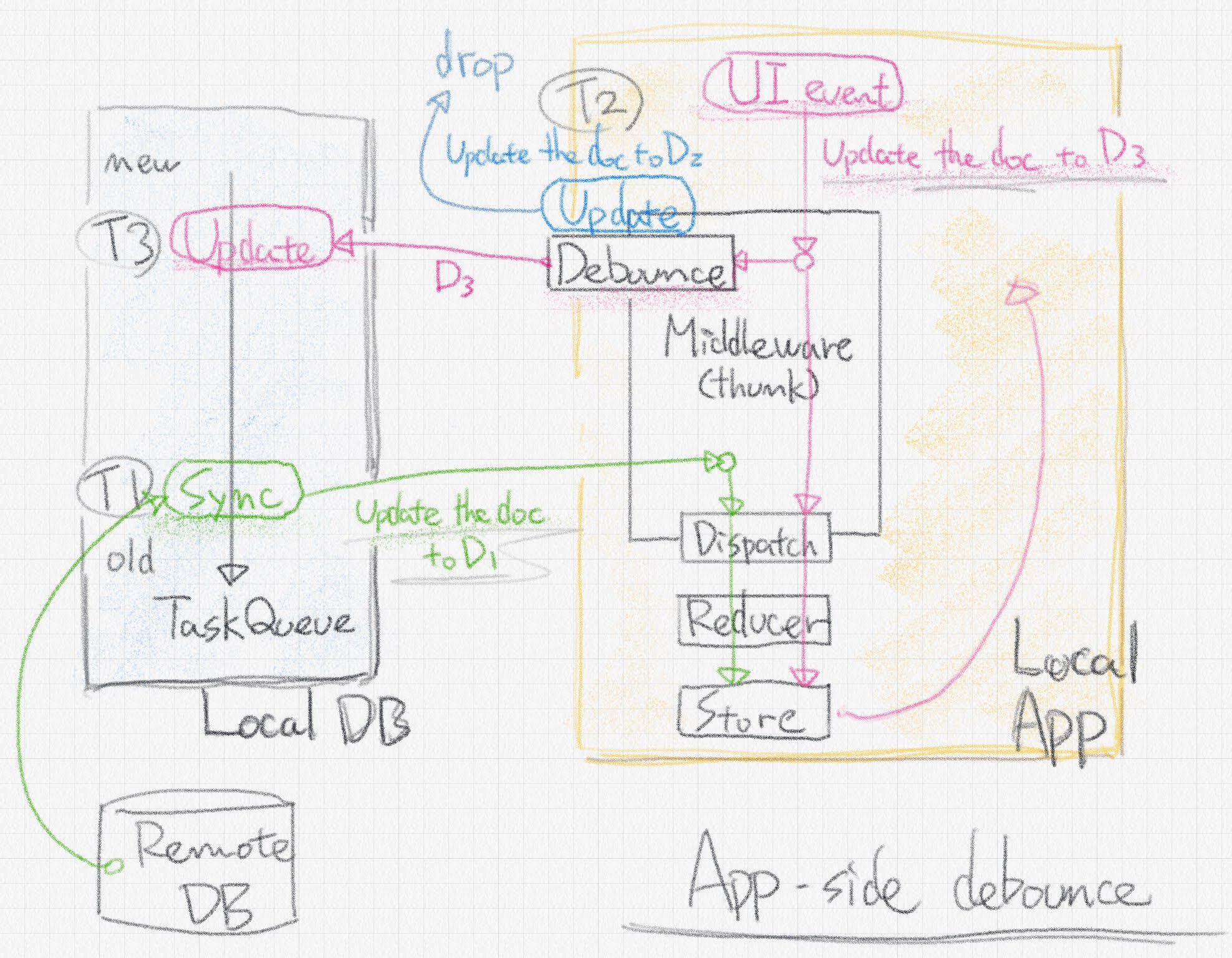
The middleware needs to be locked exclusively to determine whether updates due to UI events or synchronization events should be stored in the store. Tasks in the diagram are enqueued in the order T1, T2, T3. The middleware can solve the race case by comparing the synchronization time (T1) with the scheduled execution time (T3), dropping the data at the older time, and storing the data at the latest time in the store.
Here, if the middleware uses debounce, the debounce queue and timer are also included in the critical section, complicating exclusive locking.
However, with debounce on the database-side, locking the middleware becomes simple.
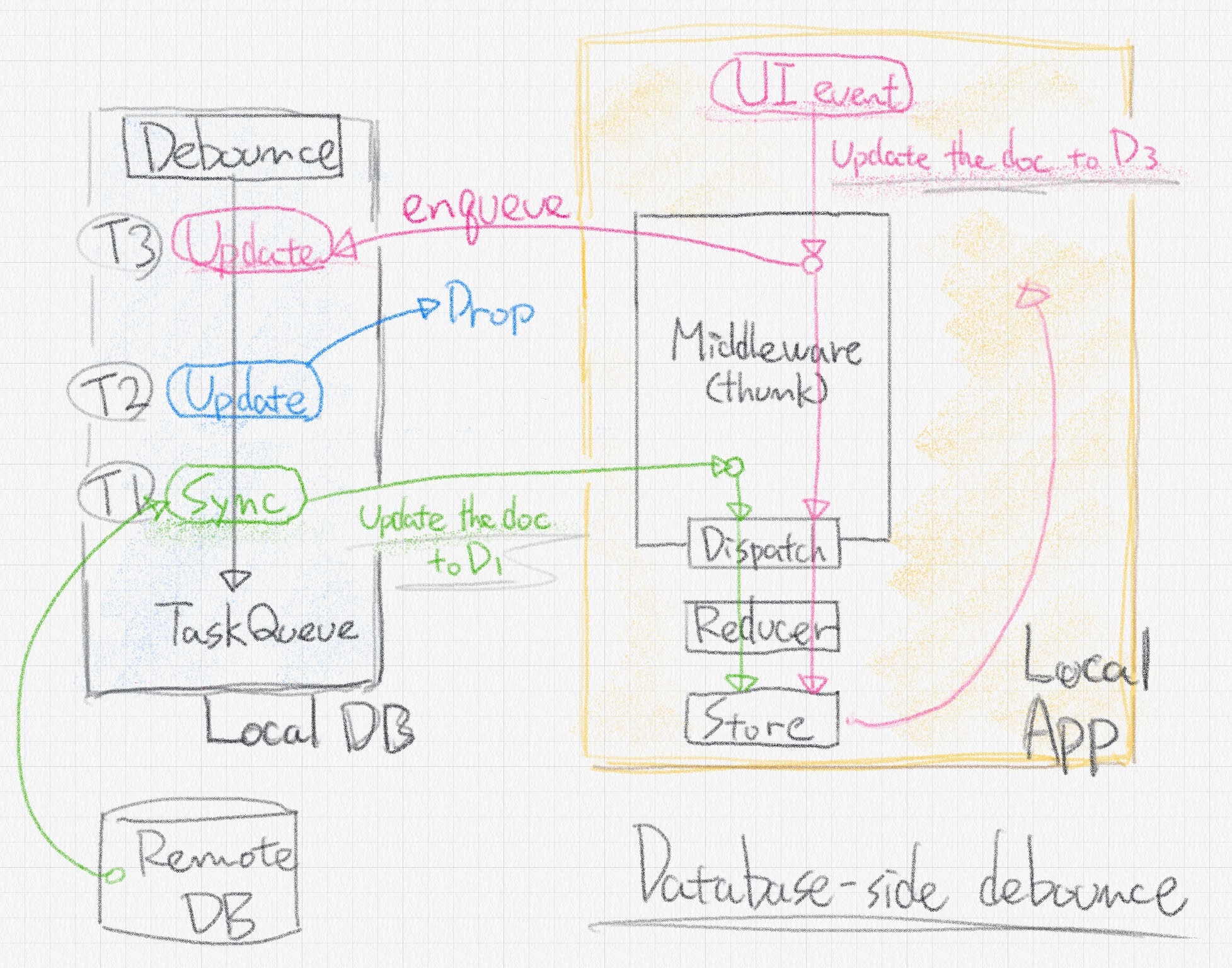
Debouncing on the database side may sound strange, but I think it can be considered for a document database that is updated on a per-document basis.
It is an experimental implementation and may be changed in the future.